
Project Summary
Organization: PEcAn Project
Mentors: Rob Kooper(@robkooper), Istem Fer(@istfer)
Student: Nihar Sanda(https://koolgax99.github.io)(@koolgax99)
My Proposal
The project aims at improving and extending the current PEcAn REST API’s by making it more robust and dynamic from the user’s perspective. The security of the API’s will also be improved by introducing API KEY management system, rate limitng and input validation.
Pre-GSoC Period
This period was mainly focused on understanding the codebase of the PEcAn Project and the current state of the API’s. Then setting up the development environment and getting familiar with the codebase of the API’s. Then migrating the Swagger documentation to my own Postman collection.
Meanwhile, I had floated a Google Form for the community to provide their suggestions on the new API’s they would love to feature in the PEcAn API package. The suggestions included were:
- Given a pft name, run a Meta analysis and return results
- Expose the Posteriors files so that parameterizations can be shared (i.e. the files pointed to in the dbfiles -> Posteriors linkages)
- sda.enkf.multisite POST and GET
- pda.emulator and pda.emulator.ms POST and GET
Work Done in GSoC Period
My aim this summer was to build 5-6 API’s and also improve the security of the API’s by adding API Key management system for the users. Now I will give you a brief walkthrough of what work has been done in the GSoC period.
Bug Fixes and improving the pagination of the PEcAn API’s
The pagination was not up to the mark for the API’s as it was not showing appropriate results, it also had few cross API results where the results from another API were being sent to a given API. So I fixed the pagination for the API’s and also added the pagination for the API’s which were not having it.
Before
- For
/api/inputs/the response was:"next_page": "http://api.pecan.localhost:8000/api/workflows/NA50&limit=50" - Similarly, For
/api/workflows/the response was:"next_page": "http://api.pecan.localhost:8000/api/workflows/NA50&limit=50" - For
/api/runs/the response was:"next_page": "http://api.pecan.localhost:8000/api/runs/NA50&limit=50"
After
- For
/api/inputs/the response now is"next_page": "http://api.pecan.localhost:8000/api/inputs/?offset=50&limit=50" - For
/api/workflows/the response now is"next_page": "http://api.pecan.localhost:8000/api/workflows/?offset=50&limit=50" - For
/api/runs/the response now is"next_page": "http://api.pecan.localhost:8000/api/runs/?offset=50&limit=50"
Adding the Posterior API’s
A new API package was added this summer which contains the API’s for the posterior data. The API’s are as follows:
/api/posteriors/
This API lists all the posterior files that are available in the posteriors table in the PEcAn database for a given PFT. The input parameters of the API are:
- pft_id: The ID of the PFT for which the posterior files are to be listed.
- limit (otpional): The number of posterior files to be listed. Default value is 50.
- offset (optional): The offset from which the posterior files are to be listed. Default value is 0.
/api/posteriors/{posterior_id}
This api returns the porterior file that is mentioned by the user. The input parameters of the API are:
- posterior_id: The ID of the posterior file that is to be listed.
- filename (optional): The name of the file that is to be listed. Default is Null. filename specified if the id points to a folder instead of file (character). If this is passed with an id that actually points to a file, this name will be ignored.
Extending the Workflow API’s
Currently the workflow API have a functionality to download only a single file from the workflow. So I extended the functionality of the workflow API’s to download the entire workflow folder. The API’s are as follows:
/api/workflows/{id}/file-multiple/
This API downloads the ultiple files of a workflow. This comes in handy for various researchers to download multiple files from a workflow. Earlier a researcher could only download a single file at a time via the /api/workflows/{id}/file/{filename} API.
The input parameters of the API are:
id: The ID of the workflow for which the files are to be downloaded.
This API also requires a body where the name of the files are to be specified. The body should be in the following format:
{ "files": ["file1", "file2", "file3"] }For eg.
{ "files": ["pecan.xml", "workflow.R"] }
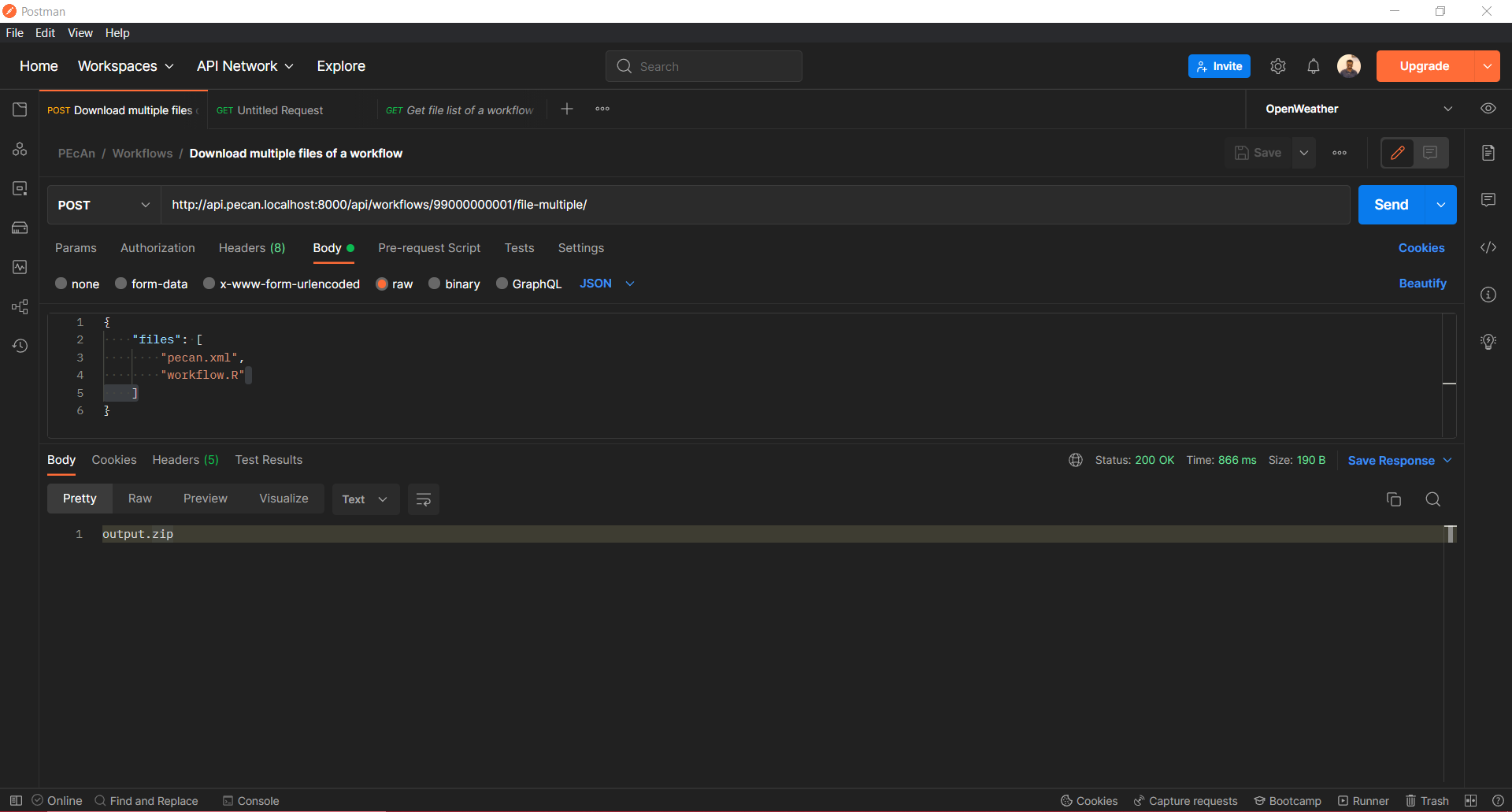
As you can see in the image above, on hitting the request a successful respnse will give you a output.zip file consisting of the files that were specified in the body.
API Key Authentication for API’s
Earlier the PEcAn API had an authentication of username and password, but this becomes a tedious task. But now, using the API key authentication the user will just have to send the API_KEY in the header and if the API_key matches the one in the database then the user will be authenticated.
The additional feature is to only authenticate the API’s which are having the POST request.
The API_KEY can be found with apikey as the parameter in the users table of the PEcAn database. The API_KEY is a 32 character long string.
This authentication can be useful to track user metrics in the future, and also to prevent the user from making too many requests to the API’s.
Meta-Analysis API
The meta-analysis API package is a new package in the PEcAn API which contains the API’s for the meta-analysis. THe API’s have distinct feature like running a meta-analysis. The API’s are as follows:
/api/ma/run/
This API will run a desired a meta-analysis based on the settings file that is provided to it. The request should contain a xml type body which contains the settings file. The sample settings file is as shown below:
<?xml version="1.0"?>
<info>
<notes/>
<userid>-1</userid>
<username/>
<date>2022/09/29 15:46:00 +0000</date>
</info>
<outdir>/data/workflows/PEcAn_99000000004</outdir>
<database>
<bety>
<user>bety</user>
<password>bety</password>
<host>postgres</host>
<port>5432</port>
<dbname>bety</dbname>
<driver>PostgreSQL</driver>
<write>true</write>
</bety>
<dbfiles>/data/dbfiles</dbfiles>
</database>
<pfts>
<pft>
<name>temperate.coniferous</name>
</pft>
</pfts>
<meta.analysis>
<iter>3000</iter>
<random.effects>
<on>FALSE</on>
<use_ghs>TRUE</use_ghs>
</random.effects>
</meta.analysis>
<ensemble>
<size>1</size>
<variable>NPP</variable>
<samplingspace>
<parameters>
<method>uniform</method>
</parameters>
<met>
<method>sampling</method>
</met>
</samplingspace>
</ensemble>
<model>
<id>1000000014</id>
</model>
<workflow>
<id>99000000004</id>
</workflow>
<run>
<site>
<id>772</id>
<met.start>1999-01-01 00:00:00</met.start>
<met.end>2003-12-31 00:00:00</met.end>
</site>
<inputs>
<met>
<id>5000000006</id>
</met>
</inputs>
<start.date>2000/01/01</start.date>
<end.date>2000/12/31</end.date>
</run>
<host>
<name>localhost</name>
<rabbitmq>
<uri>amqp://guest:guest@rabbitmq/%2F</uri>
<queue>SIPNET_r136</queue>
</rabbitmq>
</host>
The output of this API is a content from the post.distns.MA.Rdata file. A sample output is as shown below.
{
"status": "Meta Analysis ran successfully",
"data": [
{
"distn": "beta",
"parama": 2.63,
"paramb": 6.52,
"n": 0,
"_row": "growth_resp_factor"
},
{
"distn": "gamma",
"parama": 4599.0942,
"paramb": 13859.064,
"n": 363,
"_row": "leaf_turnover_rate"
},
{
"distn": "gamma",
"parama": 130531.937,
"paramb": 7335.3038,
"_row": "root_respiration_rate"
},
{
"distn": "norm",
"parama": 0.6032,
"paramb": 0.0322,
"_row": "root_turnover_rate"
},
{ "distn": "norm", "parama": 16.8391, "paramb": 0.1774, "_row": "Amax" },
{
"distn": "norm",
"parama": 1.4098,
"paramb": 0.0252,
"_row": "leaf_respiration_rate_m2"
},
{
"distn": "gamma",
"parama": 1571.2799,
"paramb": 303.327,
"n": 455,
"_row": "SLA"
},
{
"distn": "norm",
"parama": 50.4784,
"paramb": 0.182,
"n": 291,
"_row": "leafC"
},
{ "distn": "norm", "parama": 0, "paramb": 3, "_row": "Vm_low_temp" },
{ "distn": "unif", "parama": 0.6, "paramb": 0.9, "_row": "AmaxFrac" },
{ "distn": "unif", "parama": 5, "paramb": 40, "_row": "psnTOpt" },
{
"distn": "unif",
"parama": 0,
"paramb": 100,
"_row": "stem_respiration_rate"
},
{
"distn": "unif",
"parama": 0.38,
"paramb": 0.62,
"_row": "extinction_coefficient"
},
{
"distn": "unif",
"parama": 4,
"paramb": 27,
"_row": "half_saturation_PAR"
},
{ "distn": "unif", "parama": 0.01, "paramb": 0.25, "_row": "dVPDSlope" },
{ "distn": "unif", "parama": 1, "paramb": 3, "_row": "dVpdExp" },
{
"distn": "unif",
"parama": 1.4,
"paramb": 2.6,
"_row": "veg_respiration_Q10"
},
{
"distn": "unif",
"parama": 1.4,
"paramb": 5,
"_row": "fine_root_respiration_Q10"
},
{
"distn": "unif",
"parama": 1.4,
"paramb": 5,
"_row": "coarse_root_respiration_Q10"
}
]
}
SDA ENKF Multisite (WIP)
This is a POST and GET API for the PEcAn’s sda.enkf.multisite function in the State Data Assimilation package. This function allows for assimilation of observed data at multiple sites at the same time. It is currently in progress as we have to discuss about how to parse the inputs via the API.
- The API will take in list inputs of means and covariances.
PDA Emulator (WIP)
This is a POST and GET API for the PEcAn’s pda.emulator and also for the pda.emulator.ms function in the Parameter Data Assimilation package. This function runs the emulator on multiple sites in three modes: local, global, hierarchical.
Future Scope
In future I would be contributing weekly to the PEcAn Porject for the betterment of the community. Also completing the other suggestions that were given to me by the community. I would also be maintaining the PEcAn API packages and thus continue to work with the team to develop many new API’s.
Life @PEcAn
My summer experience @PEcAn was incredible and a great learning experience for me. Especially to work with genius minds who are working towards a better Ecosystem as a passion. The PEcAn bi-weekly meetings are a whole new experience where you get to interact with so many researchers and scientists from all over the world and take their feedback on your work. The people @PEcAn are very welcoming and helpful.
Giving Back to the community
Its always important to give back to the community what it has given us. I would like to give back to the community by contributing to the PEcAn project and also by helping the new contributors to this organisation. I would also like to help the community by writing blogs and tutorials on the PEcAn project.
Recently, I also gave a talk about OpenSource, How to crack GSoC and write an application for it, my experience of GSoC at PEcAn in my university. The students were delighted to know about the project and the community. More than 100 had attended the talk and it was a great learning experience for them. Few highlights of the talk can be seen in the pictures below.


Acknowledgement
Students should take advantage of Google Summer of Code as a great way to develop their coding knowledge and collaboration skills. The student benefits from being able to choose the project they wish to work on and develop their skills in the targeted areas.
I wanted to express my gratitude to my mentors for providing consistent advice throughout the programme. I appreciate you giving me this fantastic chance. Future collaboration with you on open source projects is something I’m looking forward to.
I appreciate GSoC for giving me the chance to work in the wonderful open source community.